Obvious Ownership: A Sensible Humane Registry
Imagine yourself as an engineer who just joined SoundCloud. Besides meeting your colleagues and getting your new laptop, badge, and that cool branded hoodie, the first weeks at work will be about exploration. Onboarding involves a lot of “looking around”: finding mentorship, getting to know the company’s culture, and exploring codebases — and most likely, you’ll want to contribute code too!
The first question you might ask is “What do I even work on?”. With time, you’ll identify a few sibling teams you interact with often — because you either consume their data or provide them with yours. So now, it’s important to know not only what you work on, but also which folks depend on you, and vice versa.
As SoundCloud has grown rapidly — both in the number of people and in software — we’ve identified “Who owns X?” as a recurring question coming primarily from new joiners, but also from tenured folks. You can imagine how this information can also be useful to an EM advocating for more people on their team, or to an incident-response team when diagnosing an outage scenario. We needed an obvious way to consult system ownership, so we decided to build a humane registry.
Humane Registries
If you’ve been around service-oriented architecture (SOA) before, you may have heard of service directories. The WS-* standard for them is called Universal Description, Discovery and Integration (UDDI), and it’s a complicated mix of service discovery and human readable information. A snippet from a classic book describes UDDI:
“At its core, UDDI consists of two parts (…) a technical specification for building a distributed directory of businesses and web services [that] enables anyone to search [its] data. It also enables any company to register itself and its services.
The data captured within UDDI is divided into three main categories:
- White pages: This includes general information about a specific company—for example, business name, business description, contact information, address and phone numbers.
- Yellow pages: This includes general classification data for either the company or the service offered. For example, this data may include industry, product, or geographic codes based on standard taxonomies.
- Green pages: This category contains technical information about a web service. Generally, this includes a pointer to an external specification and an address for invoking the web service (…) UDDI can be used to describe any service, from a single web page or email address all the way up to SOAP, CORBA, and Java RMI services.”
Humane registries play a similar role, but they focus on human-readable information. These systems are pretty much what OpenHub does, i.e. automatically derive as much information as possible from a project based on its code and metadata, and add a layer of prose via wiki-like tools.
The whole point is that a humane registry acknowledges that while automation and APIs are crucial for an SOA architecture, people talking to each other is still the most important and effective collaboration we have. The registry helps start effective conversations; it doesn’t try to eliminate them.
Services Directory
When planning our implementation, we had a single requirement: The registry must enable finding out which systems a team owns and who the owners of given systems are. As a stretch goal, we were also interested in exposing dependencies across systems and teams.
To deliver, we introduced the concept of “manifest files,” which would serve as entity metadata descriptors: Each code repository should have at least one manifest file. Naturally, one of the fields in the manifest file would be the owner team for that specific software piece. These files would then be ingested by the registry on a recurring basis, in order to form an up-to-date software-catalog graph that could then be rendered into the registry’s UI:
{
"_schema": "soundcloud/applicationmanifest/v1",
"name": "periskop",
"description": "Language agnostic exception aggregator for microservice environments.",
"owner": "engineering-productivity-team",
"type": "tool",
"status": "production"
}Our humane registry was named Services Directory. Of course, later on we learned we were interested in cataloguing more than just services.
")
More Automation: A Schema Definition
By introducing manifest files and ingestion through a services directory, we attained our goal of having a central index for our software pieces. What we observed, though, is that maintaining correctness of the data over time became a challenge: teams get renamed, systems are handed over, etc. In addition, small things like typos, or different ways of referring to teams — as exemplified by the screenshot above with user-growth and User Growth team names — prevented our aggregation logic from providing good results.
Well, there are existing technologies built specifically for the purpose of validating documents. So we began to define a vocabulary of properties our ingestion system expected, and we encoded them in a schema:
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "SoundCloud's Application Manifests Schema",
"type": "object",
"required": [
"owner",
…
],
"properties": {
"owner": {
"type": "string"
},
…
}The next step was to provide a validation engine based on the predefined schema, running it against the manifest files. In the spirit of continuous delivery, we could hook that up in our CD pipelines as part of the linting stage: Our manifests would be validated against each individual change to these repositories, assuring they never drift from the schema.

As a bonus, by relying on JSON Schema as a schema-description standard, we were also able to provide ahead-of-commit support (developer experience FTW) by leaning on autocompletion of popular code editors.
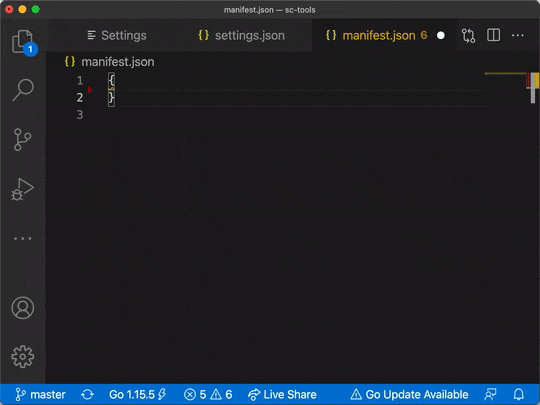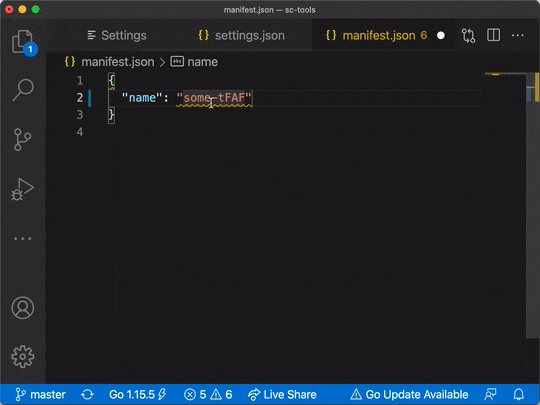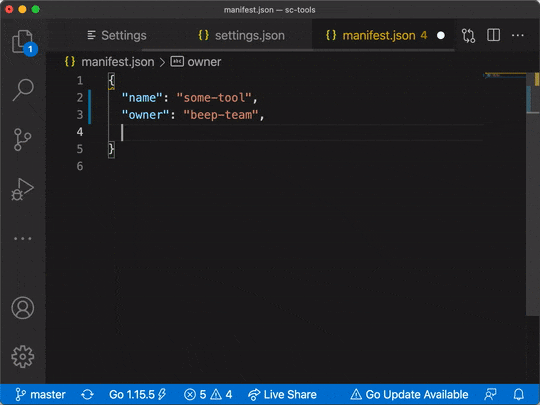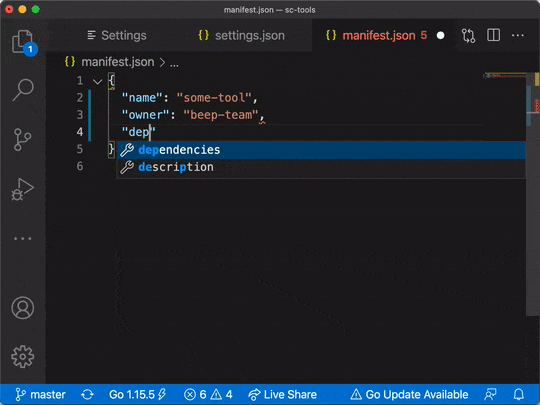
On top of executing single-pass manifest validation, having an automated way to check for schema compliance opens the door to a more holistic view of the company’s software catalog. Services Directory ingests manifest files, checks syntactically for unwanted properties, and has the ability to report back semantically on values.
It was easy to set up a validation step to compare owner values with a knowingly good list of existing teams, sourced from our LDAP server. This means a software piece with an invalid team name gets rejected in a CI environment. It also means we could provide teams with a comprehensive view of their ownership. A background job exports Prometheus metrics on the manifest validation engine, which powers a dashboard, like shown below.


What Else?
Ensuring code ownership visibility is just one aspect of Services Directory, our humane registry. Including manifest files as entity descriptors became ingrained in SoundCloud’s engineering culture, and as schema providers, we have a way to ensure standardization across our vast code landscape.
Since introducing validation logic, we’ve seen higher engagement with Services Directory and identified it as a central piece in our developer experience tooling offering. Various teams and individuals have reached out with feature requests and integration ideas, which we’ve been partnering on to provide — we’ll share more about that in the future.